Awesome PocketSDR (reducing processing time with FFTW)
Introduction
New version 0.7 of PocketSDR, a software defined radio positioning satellite reception package, has been released. Due to the high speed of this version upgrade, simultaneous tracking of many satellite signals can be expected. Since satellite positioning is based on simultaneous observation of multiple satellite radiowaves, we want to track more satellite signals. Moreover, I am happy that the display on the console is in color.
Most of this applications are written in Python, but some codes, such as error correction, are written in C.
FFTW
The version of PocketSDR makes calls to the external C libraries FFTW and libusb from the sdr_func.py. FFTW is a software library that represents the fastest Fourier transform in the west and realizes the fast Fourier transform (FFT). To install these libraries, run pacman -S mingw-w64-x86_64-fftw on Windows and sudo apt install libfftw3-dev libusb-1.0-0-dev on Ubuntu Linux.
Use on macOS
The target OS of the PocketSDR applications are Windows and Ubuntu Linux. However, since the main part is written in Python, we can use them without considering a specific CPU architecture.
In the new version of Pocket SDR, Makefiles that uses for compiling the C language library have been added. So we can port them more easily on other operating systems. Therefore, I tried to automatically determine the OS in the Makefile so that we can used it on macOS both with Intel CPU and M1 CPU. The method of creating a shared library on macOS is the same as an article Awesome PocketSDR (pocket_trk edition).
Also, on macOS with Homebrew installed, execute brew upgrade; brew install fftw libusb to install the above FFTW and libusb.
Some changes to the Python code are required to make it available on macOS. I forked the source code from the GitHub page of Professor Tomoji Takasu of Tokyo University of Marine Science and Technology, and published the code including the compiled shared library on my GitHub page. Please download and use it at git checkout https://github.com/yoronneko/PocketSDR. To see the difference between them, please run git diff 5eb2e79.
In this version, the function get_const_int () that extracts constants from RTKLIB has been added to the Python wrapper code sdr_rtk.py. For this reason, the previously created librtk.so (Windows or Linux) or librtk.dylib (macOS) cannot be used as is, so please replace it with the one for this version.
Detecting OS in Makefile
There are several ways to detect the OS of Windows, Linux, macOS (also denoted as Darwin) and they are:
- to use
-dumpmachineoption in C compiler (kosh04/os.mk), - to use the shell command
uname(OS detection in makefile, Makefile for multi platform, make for cross platform), and - to use the environment variable
OSand the shell commanduname(difference correction in each Makefile environment, OS detecting makefile).
Here, the method of 3 is used. The PocketSDR library creation directory is lib/build.
To actually create a shared library, we have to make a distinction between Intel CPUs and M1 CPUs. So, for example, I added the following OS detection to the Makefile of, for example, libfec. In this example, the extension EXTSH and the installation directory INSTALL of the shared library are used for OS dependent variables.
...
ifeq ($(OS),Windows_NT)
#! for Windows
INSTALL = ../win32
EXTSH = so
else
ifeq ($(shell uname -s),Linux)
#! for Linux
INSTALL = ../linux
EXTSH = so
else ifeq ($(shell uname -s),Darwin)
ifeq ($(shell uname -m),x86_64)
#! for macOS Intel
INSTALL = ../darwin_x86
CONFOPT = --target=x86-apple-darwin --build=x86-apple-darwin
else ifeq ($(shell uname -m),arm64)
#! for macOS Arm
INSTALL = ../darwin_arm
endif
EXTSH = dylib
endif
endif
TARGET = libfec.$(EXTSH)
...
$(TARGET) :
DIR=`pwd`; \
cd $(SRC); \
./configure $(CONFOPT); \
...
The configure script of the error correction library libfec fails to determine the OS of Intel Mac, so for Intel Mac, the environment variable CONFOPT has been set to the --target option and --build. I'm assigning the option so as to make the configure script to correctly determine the OS.
Also, the current Homebrew (version 3.3.15, 2022-02-18) when using M1 Mac does not seem to automatically set the INCLUDE and LDLIBS paths for the installed library. Therefore, I added these paths in the Makefile.
It may not be possible to expect speedup by FFTW on macOS
For this acceleration, turn on all acceleration features with the -march = native option during C compilation of the Fast Fourier Transform library libsdr.so, and use the Intel CPU with the -DAVX2 option for enabling the compiler to use the AVX2 (Intel Advanced Vector Extensions 2) instruction set.
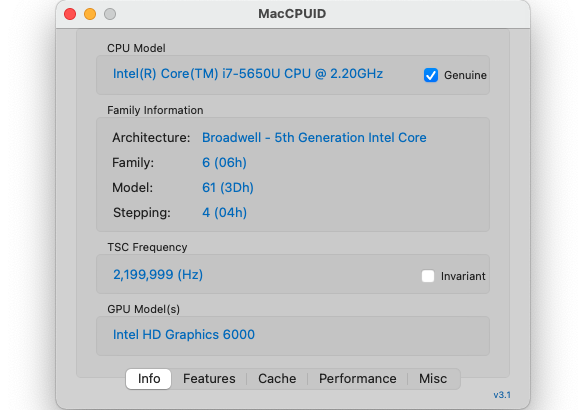
The LLVM (low level virtual machine) Clang compiler on macOS does not use the -march=native option even on Intel CPUs. The CPU of my Macbook Air is Intel Core i7-5650U and has an AVX2 instruction set. Therefore, I forcibly turned on AVX2 with -march=haswell and compiled it. AVX2 was introduced in the Haswell generation of Intel CPUs, so it’s a way to set Haswell as an architecture. However, this C code took about 1.5 times slower than the Python code took. The result of Intel MacCPUID (CPU information reading tool) and the execution example of pocket_trk.py are as follows.
An example execution of FFTW off
$ ./pocket_trk.py ../sample/L6_20211226_082212_12MHz_IQ.bin -prn 194 -f 12 -sig L6D
TIME(s) SIG PRN STATE LOCK(s) C/N0 (dB-Hz) COFF(ms) DOP(Hz) ADR(cyc) SYNC #NAV #ERR #LOL NER
30.40 L6D 194 LOCK 30.39 47.5 ||||||||||| 3.8275431 -91.0 -2786.4 -BF- 29 0 0 0
TIME(s) = 62.924
An example execution of FFTW on(-march=haswell、-DAVX2)
./pocket_trk.py ../sample/L6_20211226_082212_12MHz_IQ.bin -prn 194 -f 12 -sig L6D
TIME(s) SIG PRN STATE LOCK(s) C/N0 (dB-Hz) COFF(ms) DOP(Hz) ADR(cyc) SYNC #NAV #ERR #LOL NER
30.40 L6D 194 LOCK 30.39 47.5 ||||||||||| 3.8275431 -91.0 -2786.4 -BF- 29 0 0 0
TIME(s) = 93.682
On the M1 CPU, the -march=native option of the Clang C language compiler is not available, nor is AVX2 available.
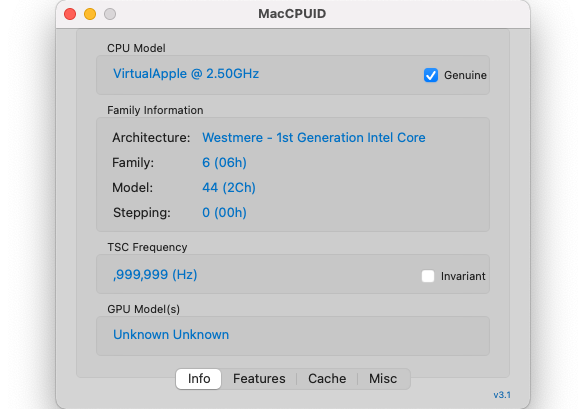
So I tried compiling and running without -DAVX2, but there was almost no difference in execution time between with and without FFTW offload.
For Intel CPUs of Haswell generation or later, the presence or absence of a function called FMA3 (Fused Multiply Add 3) that executes a product-sum operation with one instruction and its implementation are also important for matrix calculation and fast Fourier transform, but this function is implemented. It seems that some CPUs do not have it. In order to enable FMA3 on FFTW, it seems that we have to build it ourselves without relying on the package. There is a trade-off between tuning and environment-dependent exclusion.
Apple M1 CPU is still fast
Even in the macOS version, there is a possibility that it can be speedup up by tuning the option of FFTW, so I always used FFTW here. You can cancel the FFTW offload at any time by changing LIBSDR_ENA = True to LIBSDR_ENA = False in the sdr_func.py code in the Python directory.
Using the sample data included in PocketSDR and pocket_trk.py, I tried to decode the L6D signal (CLAS: centimeter level augmentation service) sent from the Quasi-zenith satellite (QZS) 2.
$ ./pocket_trk.py ../sample/L6_20211226_082212_12MHz_IQ.bin -prn 193-199 -f 12 -sig L6D -p
Although the number of channels in this example is 1, it seems that the L6D signal can be tracked in near real time even under heavy load with animation.
Then I turn off the animation and measure the processing time.
$ ./pocket_trk.py ../sample/L6_20211226_082212_12MHz_IQ.bin -prn 193-199 -f 12 -sig L6D
TIME(s) SIG PRN STATE LOCK(s) C/N0 (dB-Hz) COFF(ms) DOP(Hz) ADR(cyc) SYNC #NAV #ERR #LOL NER
30.40 L6D 194 LOCK 30.39 47.5 ||||||||||| 3.8275431 -91.0 -2786.4 -BF- 29 0 0 0
TIME(s) = 9.831
The sample data is for about 30 seconds, and this execution time is about 9.8 seconds. On the other hand, the execution time with 60 seconds of data by Professor Takasu was 18.2 seconds, so we may say that it is almost the same as the result of this Apple M1 CPU (2.5 GHz) without tuning. The execution time without FFTW offload was 10.1 seconds.
$ ./pocket_trk.py ../sample/L6_20211226_082212_12MHz_IQ.bin -prn 194 -f 12 -sig L6D
TIME(s) SIG PRN STATE LOCK(s) C/N0 (dB-Hz) COFF(ms) DOP(Hz) ADR(cyc) SYNC #NAV #ERR #LOL NER
30.40 L6D 194 LOCK 30.39 47.5 ||||||||||| 3.8275431 -91.0 -2786.4 -BF- 29 0 0 0
TIME(s) = 10.130
With the Makefile in place, I could now try and error in simple steps. PocketSDR has a lot of features I haven’t tried yet. I will enjoy the treasure hunt in PocketSDR.
Related article(s):
- Awesome Pocket SDR (Effective use of configuration files) 30th April 2025
- Pocket SDR captured data 25th April 2025
- Awesome Pocket SDR (realtime positioning function) 13th October 2024
- Galileo E6B signal reception with Pocket SDR, a open source software-defined radio 27th January 2023
- Failure in reflow soldering 19th January 2023
- Pocket SDR hardware production (part 3) 30th September 2022
- Pocket SDR hardware production (part 2) 14th September 2022
- Pocket SDR hardware production (part 1) 4th September 2022
- Awesome PocketSDR (order of hardware parts) 9th April 2022
- I want to use bladeRF with PocketSDR AP, part 2 16th March 2022
- I want to use bladeRF with PocketSDR AP 5th March 2022
- Awesome PocketSDR (snapshot positioning) 23rd February 2022
- Awesome PocketSDR (L6 band signal decode) 19th January 2022
- Awesome PocketSDR (pocket_trk) 28th December 2021
- Awesome PocketSDR(pocket_acq) 4th December 2021