PocketSDRすごい(FFTWによる高速化)
はじめに
ソフトウェア無線(SDR: software defined radio)による測位衛星受信パッケージ「PocketSDR」の新バージョン0.7が公開されました。このバージョンアップの高速化により、多くの衛星信号の同時追尾が望めます。衛星測位は、複数衛星電波の同時観測に基づきますので、より多くの衛星信号を追尾したいのです。しかもコンソールの表示がカラーになり嬉しいです。
このアプリケーションの大部分はPythonで記述されていますが、誤り訂正などの一部のコードはC言語で記述されています。
FFTW
新バージョンのPocketSDRは、pythonディレクトリにあるsdr_func.pyからの外部C言語ライブラリFFTWとlibusbの呼び出しを行います。FFTWは、西洋最速フーリエ変換(the fastest Fourier transform in the west)を表し、高速フーリエ変換(FFT: fast Fourier transform)を実現するソフトウェアライブラリです。これらのライブラリを導入するためには、Windowsではpacman -S mingw-w64-x86_64-fftwを、Ubuntu Linuxではsudo apt install libfftw3-dev libusb-1.0-0-devを実行します。
macOSでの利用
PocketSDRアプリケーションの対象OSは、WindowsとUbuntu Linuxです。しかし、主要部分がPythonで記述されているため、特定CPUアーキテクチャに依存することなく利用できます。
新バージョンのPocketSDRでは、C言語ライブラリ部分をコンパイルするMakefileが追加されたので、より容易に他OSでも利用できるようになりました。そこで、Makefileの中でOSを自動判定して、Intel CPUとM1 CPUのmacOSでも利用できるようにしてみました。macOSでの共有ライブラリ作成方法はPocketSDRすごい(pocket_trk編)と同様です。
また、Homebrewを導入したmacOSにて、上述のFFTWとlibusbを導入するためには、brew upgrade; brew install fftw libusbを実行します。
macOSでも利用できるようにするためには、Pythonコードの一部変更が必要です。ソースコードを東京海洋大学の高須知二先生のGitHubページからフォークし、コンパイル済みの共有ライブラリも含めたコードを私のGitHubページ にて公開しています。git checkout https://github.com/yoronneko/PocketSDRなどでダウンロードしてご利用ください。これと、高須先生のバージョン0.7との差分を表示するには、git diff 5eb2e79を実行します。
なお、このバージョンでは、RTKLIBから定数を抽出する関数get_const_int()がRTKLIBのPythonラッパーコードsdr_rtk.pyに追加されました。このため、以前に作成したlibrtk.so(WindowsまたはLinux)やlibrtk.dylib(macOS)をそのまま利用できませんので、このバージョン用のものに置き換えてください。
MakefileでのOSの自動判定
MakefileにてWindows、Linux、macOS(Darwinとも呼ばれます)のOSを判定するためには、
- C言語コンパイラの
-dumpmachineオプションを利用する方法(kosh04/os.mk) - シェルの
unameを利用する方法(makefile でのOS条件分岐、マルチプラットフォーム向けのMakefileは闇、クロスプラットフォームで make) - 環境変数
OSとシェルのunameを組み合わせる方法(Makefile環境毎の違いを補正、OS detecting makefile)
があります。ここでは3.の方法を利用します。PocketSDRのライブラリ作成ディレクトリはlib/buildです。
実際の共有ライブラリ作成には、Intel CPUと、M1 CPUとを区別しなければなりません。そこで、例えばlibfecのMakefileに次のようなOS判定を追加しました。この例では、判定OSに応じて、共有ライブラリの拡張子EXTSHとインストールディレクトリINSTALLを設定しています。
...
ifeq ($(OS),Windows_NT)
#! for Windows
INSTALL = ../win32
EXTSH = so
else
ifeq ($(shell uname -s),Linux)
#! for Linux
INSTALL = ../linux
EXTSH = so
else ifeq ($(shell uname -s),Darwin)
ifeq ($(shell uname -m),x86_64)
#! for macOS Intel
INSTALL = ../darwin_x86
CONFOPT = --target=x86-apple-darwin --build=x86-apple-darwin
else ifeq ($(shell uname -m),arm64)
#! for macOS Arm
INSTALL = ../darwin_arm
endif
EXTSH = dylib
endif
endif
TARGET = libfec.$(EXTSH)
...
$(TARGET) :
DIR=`pwd`; \
cd $(SRC); \
./configure $(CONFOPT); \
...
誤り訂正ライブラリlibfecのconfigureスクリプトは、Intel MacのOS判定に失敗しますので、Intel Mac利用時には環境変数CONFOPTに--targetオプションと--buildオプションを代入して、configureスクリプトに対してOSを認識させています。
また、M1 Mac利用時の現状のHomebrew(バージョン3.3.15、2022-02-18)では、導入したライブラリに対するINCLUDEとLDLIBSのパスを自動設定してくれないようです。メンテナンス性が悪くなり残念ですが、Makefileにてこれらのパスを追加しています。
macOSではFFTWによる高速化は望めないかも
この高速化では、高速フーリエ変換ライブラリlibsdr.soのCコンパイル時に-march=nativeオプションにてすべての高速化機能をオンにし、-DAVX2にてIntel CPUのAVX2(Intel Advanced Vector Extensions 2)機能をオンにしています。
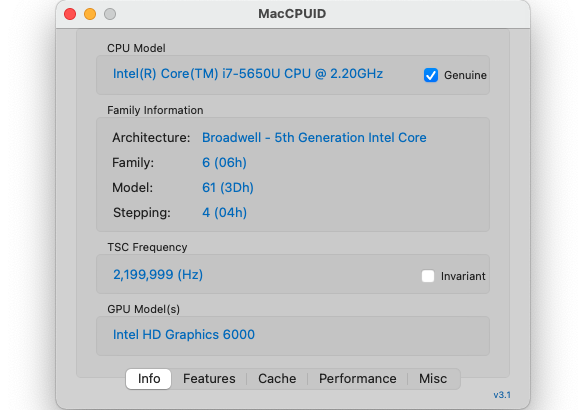
macOSのLLVM(low level virtual machine)Clang(クラング)コンパイラでは、Intel CPUであっても-march=nativeが利用でません。私の利用しているMacbook AirのCPUは、Intel Core i7-5650Uであり、AVX2命令セットを持っています。そこで、-march=haswellにて強制的にAVX2をオンにしてコンパイルしました。AVX2はIntel CPUのHaswell世代から導入されたので、Haswellをアーキテクチャとして設定する方法です。しかし、Pythonコードと比較して、このCコードは約1.5倍の時間を要しました。Intel MacCPUID(CPU情報読み出しツール)の結果とpocket_trk.pyの実行例は次の通りです。
FFTWオフでの実行例
$ ./pocket_trk.py ../sample/L6_20211226_082212_12MHz_IQ.bin -prn 194 -f 12 -sig L6D
TIME(s) SIG PRN STATE LOCK(s) C/N0 (dB-Hz) COFF(ms) DOP(Hz) ADR(cyc) SYNC #NAV #ERR #LOL NER
30.40 L6D 194 LOCK 30.39 47.5 ||||||||||| 3.8275431 -91.0 -2786.4 -BF- 29 0 0 0
TIME(s) = 62.924
FFTWオンでの実行例(-march=haswell、-DAVX2)
./pocket_trk.py ../sample/L6_20211226_082212_12MHz_IQ.bin -prn 194 -f 12 -sig L6D
TIME(s) SIG PRN STATE LOCK(s) C/N0 (dB-Hz) COFF(ms) DOP(Hz) ADR(cyc) SYNC #NAV #ERR #LOL NER
30.40 L6D 194 LOCK 30.39 47.5 ||||||||||| 3.8275431 -91.0 -2786.4 -BF- 29 0 0 0
TIME(s) = 93.682
M1 CPUでは、Clang C言語コンパイラの-march=nativeオプションを利用できなく、AVX2も利用できません。
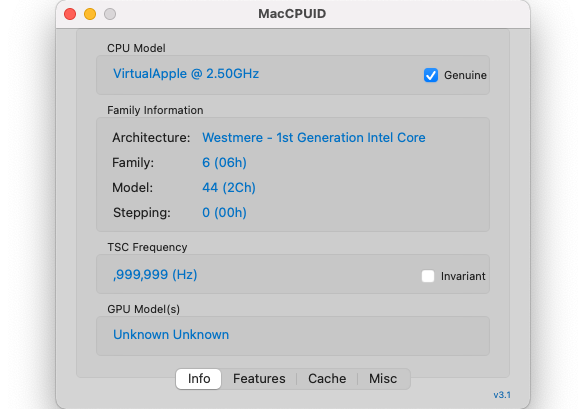
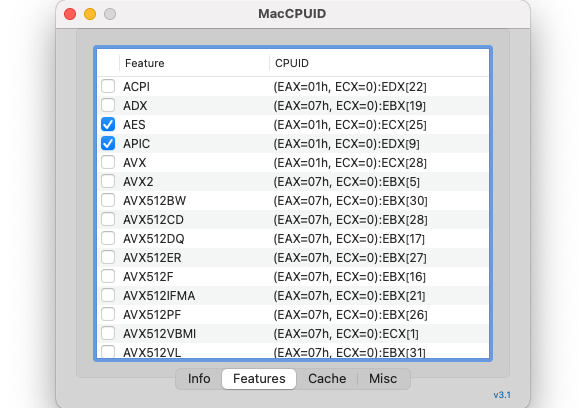
そこで、-DAVX2なしでコンパイルして実行してみましたが、FFTWオフロードありとなしとの実行時間差はほとんどありませんでした。
Haswell世代以降のIntel CPUならば、FMA3(Fused Multiply Add 3)という積和演算を1命令で実行する機能の有無とその実装も行列計算や高速フーリエ変換には重要ですが、この機能が実装されていないCPUもあるそうです。FFTWにてFMA3を有効にするためには、パッケージに頼らずに、自らビルドしなければならないようです。チューニングと環境依存排除とは、トレードオフの関係があります。
Apple M1 CPUはやっぱり速い
macOS版でもFFTWのオプションチューニングにより高速化できる可能性がありますので、ここでは常にFFTWを利用するようにしました。Pythonディレクトリにある、sdr_func.pyコード中のLIBSDR_ENA = TrueをLIBSDR_ENA = Falseにすれば、いつでもFFTWオフロードをキャンセルできます。
PocketSDR付属のサンプルデータとpocket_trk.pyを用いて、みちびき2号機のL6D信号(CLAS: centimeter level augmentation service)をデコードしてみました。
$ ./pocket_trk.py ../sample/L6_20211226_082212_12MHz_IQ.bin -prn 193-199 -f 12 -sig L6D -p
この例のチャネル数は1ではあるものの、アニメーション付きの負荷の高い状態でも、ほぼリアルタイムでL6D信号を追尾できそうです。
次に、アニメーションをオフにして、処理時間を計測します。
$ ./pocket_trk.py ../sample/L6_20211226_082212_12MHz_IQ.bin -prn 193-199 -f 12 -sig L6D
TIME(s) SIG PRN STATE LOCK(s) C/N0 (dB-Hz) COFF(ms) DOP(Hz) ADR(cyc) SYNC #NAV #ERR #LOL NER
30.40 L6D 194 LOCK 30.39 47.5 ||||||||||| 3.8275431 -91.0 -2786.4 -BF- 29 0 0 0
TIME(s) = 9.831
サンプルデータは約30秒間のもので、この実行時間が約9.8秒です。一方、高須先生の60秒間のデータでの実行時間18.2秒でしたので、このチューニングなしのApple M1 CPU(2.5 GHz)の結果と、ほぼ互角といえます。FFTWオフロードなしの実行時間は10.1秒でした。
$ ./pocket_trk.py ../sample/L6_20211226_082212_12MHz_IQ.bin -prn 194 -f 12 -sig L6D
TIME(s) SIG PRN STATE LOCK(s) C/N0 (dB-Hz) COFF(ms) DOP(Hz) ADR(cyc) SYNC #NAV #ERR #LOL NER
30.40 L6D 194 LOCK 30.39 47.5 ||||||||||| 3.8275431 -91.0 -2786.4 -BF- 29 0 0 0
TIME(s) = 10.130
Makefileを整備していただいたので、簡単なステップで試行錯誤できるようになりました。PocketSDRには、まだ私が試していない機能がたくさんあります。少しづつ宝探しを楽しんでみます。
関連記事
- Pocket SDRすごい(設定ファイル有効活用編) 30th April 2025
- Pocket SDR収録データ 25th April 2025
- Pocket SDRすごい(リアルタイム測位機能) 13th October 2024
- Pocket SDRを用いたGalileo E6B信号の受信 27th January 2023
- リフローでやらかしました 19th January 2023
- Pocket SDRハードウェア製作(第3報) 30th September 2022
- Pocket SDRハードウェア製作(第2報) 14th September 2022
- Pocket SDRハードウェア製作(第1報) 4th September 2022
- PocketSDRすごい(パーツ購入編) 9th April 2022
- PocketSDR APにてbladeRFを使いたい(その2) 16th March 2022
- PocketSDR APにてbladeRFを使いたい 5th March 2022
- PocketSDRすごい(スナップショット測位編) 23rd February 2022
- PocketSDRすごい(L6信号デコード編) 19th January 2022
- PocketSDRすごい(pocket_trk編) 28th December 2021
- PocketSDRすごい(pocket_acq編) 4th December 2021